토론 완료
Triplegangers CEO Oleksandr Tomchuk은 토요일에 자사의 전자 상거래 사이트가 다운되었다는 알림을 받았다. 어떤 종류의 분산 서비스 거부 공격인 것처럼 보였다.
OpenAI의 봇이 그의 거대한 전체 사이트를 무자비하게 스크랩하려고 계속 시도하는 것을 발견했습니다.“우리는 65,000개 이상의 제품을 보유하고 있으며, 각 제품마다 페이지가 있습니다,”라고 Tomchuk는 TechCrunch에 말했습니다. “각 페이지에는 적어도 세 장의 사진이 있습니다.”
OpenAI는 그것 모두를 다운로드하려는 서버 요청을 '수만 차례' 보내서 수천 장의 사진과 상세한 설명과 함께 수십만 장의 사진을 다운로드하기를 시도했습니다.
“OpenAI는 데이터를 스크랩하기 위해 600개의 IP를 사용했는데, 여전히 지난 주의 로그를 분석 중이며, 아마 더 많을 수도 있습니다,”라고 그는 이 봇이 그의 사이트를 소비하기 위해 사용한 IP 주소에 대해 말했습니다.
“그들의 크롤러가 우리 사이트를 무너뜨렸습니다,”라고 그는 말했습니다. “그것은 기본적으로 DDoS 공격이었습니다.”
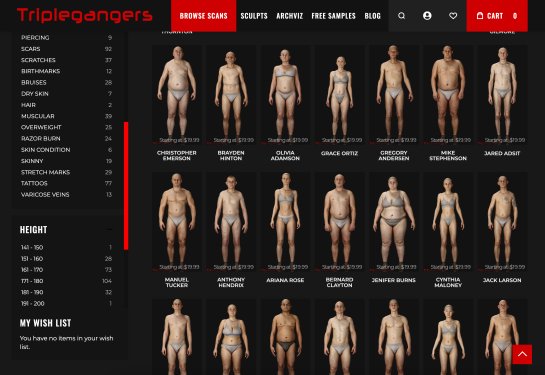
Triplegangers의 웹 사이트는 그들의 비즈니스입니다. 이 7인 직원 회사는 실제 인간 모델에서 스캔된 3D 이미지 파일이라고 하는 것을 웹의 '인간 디지털 더블'의 최대 데이터베이스를 조립하는 데 10년 이상을 보냈습니다.
3D 객체 파일 및 사진을 판매하며 손부터 머리카락, 피부 및 전신까지 모든 것을 3D 아티스트, 비디오 게임 제작자 등이 디지털적으로 진정한 인간 특성을 재현할 필요가 있는 모든 사람에게 판매합니다.
톰추크의 팀은 우크라이나에 기반을 둔 것뿐 아니라 플로리다 탬파에서 라이선스를 받았으며, 그의 사이트에는 봇이 허가 없이 이미지를 가져가는 것을 금지하는 이용 약관 페이지가 있습니다. 그런데 그것만으로는 아무것도 할 수 없었습니다. 웹 사이트는 openAI의 봇인 GPTBot이 사이트를 방치하기위한 특정 태그가 있는 제대로 구성된 로봇 텍스트 파일을 사용해야합니다. (OpenAI는 그들의 크롤러에 대한 자세한 정보 페이지에 따라 해당 파일이 제대로 구성되어 있을 때 이러한 파일을 준수한다고 말합니다.)
로봇 txt, 즉 로봇 제외 프로토콜은 검색 엔진 사이트에 어떤 영역을 색인화하는 것을 막기 위해 만들어졌습니다. OpenAI는 정보 페이지에서 이러한 파일을 자체 설정된 크롤 태그 세트와 함께 구성되었을 때 이러한 파일을 준수한다고 말하지만 업데이트된 로봇 txt 파일을 인식하는 것이 최대 24시간까지 걸릴 수 있다고도 경고합니다.
톰추크가 경험한 바에 따르면 웹 사이트가 제대로 로봇 txt를 사용하지 않으면 OpenAI와 다른 회사들이 그것들이 마음대로 스크랩할 수 있다는 것을 의미합니다. 명시적 시스템이 아닙니다.
상처가 상처에 유감스럽게도 Triplegangers는 미국 영업 시간에 OpenAI의 봇에 의해 오프라인 상태로 밀려 때렸을 뿐만 아니라, 톰추크는 봇의 활동으로 인해 AWS 요금이 급증할 것으로 예상합니다.
로봇 txt 역시 안전장치가 아닙니다. 인공지능 회사들은 자발적으로 준수합니다. Wired 조사에 따르면 다른 인공지능 스타트업 Perplexity도 지난 여름에 몇 가지 증거에서 Perplexity가 이를 준수하지 않았다는 것이 시사되자 지적을 받았습니다.
더 세세한 내용이 무슨 것이었는지 확실하지 않을 것입니다
수요일까지는 OpenAI의 봇이 여러 차례 돌아오면서 Triplegangers는 제대로 구성된 로봇 txt 파일을 설정하고 GPTBot 및 Barkrowler (SEO 크롤러) 및 Bytespider (TokTok의 크롤러)와 같은 몇 가지 다른 봇을 차단하기 위해 Cloudflare 계정을 설정하고 다른 AI 모델 회사의 크롤러를 차단했다고 톰추크는 말합니다. 목요일 아침, 사이트가 충돌하지 않았다고 그는 말했습니다.
하지만 톰추크는 OpenAI가 정확히 무엇을 성공적으로 가져갔는지 조사하는 합리적인 방법이 없으며 그 재료를 제거하는 방법도 없습니다. 그로부터 연락하는 방법을 찾지 못 하였습니다. OpenAI는 TechCrunch의 요청에 응답하지 않았습니다. 그리고 OpenAI는 최근 TechCrunch에서 보도한 바와 같이 오랫동안 약속한 탈퇴 도구를 제공하지 못했습니다.
이는 Triplegangers를 위한 특히 까다로운 문제입니다. “우리는 실제로 사람들을 스캔하기 때문에 권리가 어떤 식으로나 심각한 문제인 업종에 있습니다,”라고 그는 말합니다. 유럽의 GDPR와 같은 법률에 따르면 “그들은 웹의 누구의 사진이든 가져다 쓸 수 없습니다.”
Triplegangers의 웹 사이트는 AI 크롤러들에게 특히 혜자로운 발견이었습니다. Scale AI와 같은 몇 십억 달러 가치의 스타트업은 인간들이 이미지에 체계적으로 태그를 달아 AI를 교육하기 위해 만들어졌습니다. Triplegangers의 사이트는 사진이 세밀하게 태그가 붙여져 있습니다: 인종, 나이, 문신 대 흉흉, 모든 체형 등.
역설적으로 OpenAI 봇의 탐욕이 Triplegangers에게 그가 얼마나 노출되어있는지에 대해 알려주었습니다. 그것이 더 부드럽게 스크랩했다면, 그는 생각하지 않았을 것입니다.
“이 회사들이 '내 태그로 로봇 txt를 업데이트하면 옵트 아웃할 수 있다'고 말하면서 데이터를 크롤링할 수 있는 수단을 제공하는 허점이 있어 보입니다,”라고 톰추크는 말합니다. 그러나 그것은 시스템 삭제자가 차단하는 법을 이해하는 것에 올린 것입니다.

그는 다른 소규모 온라인 비즈니스가 AI 봇이 웹 사이트의 저작물을 가져가는지 여부를 발견하는 유일한 방법은 적극적으로 찾아보는 것이라고 말합니다. 그는 그들에 의해 고통을 받는 사람이 아닙니다. OpenAI 봇이 그들의 사이트를 충돌시키고 AWS 요금을 많이 올리는 것을 최근에 Business Insider가 보고한 다른 웹 사이트의 소유자에게 물을까요?
문제는 2024년에 지수적으로 커졌습니다. 디지털 광고 회사 DoubleVerify의 새로운 연구에 따르면 인공지능 크롤러와 스크레이퍼들은 2024년에 '일반적인 무효 트래픽'을 86% 증가시켰다. 즉 실제 사용자가 아닌 트래픽입니다.
그럼에도 불구하고 “대부분의 사이트들은 그들이 이러한 봇들에 의해 스크랩되었다는 사실을 몰라”고 톰추크는 경고합니다. “이제 우리는 이러한 봇을 발견하려고 로그 활동들을 매일 모니터해야합니다.”
생각해보면, 전체 모델이 조금 마피아를 떠올리는 구조가 있습니다: AI 봇들은 보호가 없으면 원하는 것을 가져갈 것입니다.
“그들은 데이터를 훔치는 대신 허락을 구해야합니다,”라고 톰추크는 말했습니다.
TechCrunch에는 AI에 중점을 둔 뉴스 레터가 있습니다! 매주 수요일 인박스에서 받으려면 여기에 가입하세요.


